
꿈꾸는 개발자의 devLog
[Deep Learning 논문 리뷰] Vision Transformer(ViT) : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 본문
[Deep Learning 논문 리뷰] Vision Transformer(ViT) : An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
덩화 2024. 1. 19. 17:30팀원 끼리 자체적으로 딥러닝 논문 스터디를 진행 중이다
그래서, 약 3주에 한 번씩 각자 관심 분야 논문에 대해 발표를 진행함
이 글이 여기 블로그의 100번째 글인데, 100번째 글이 첫 논문 리뷰 글이라니 !! 뭔가 좋다 :)
이 기세로 쭉쭉 가보주악 !!!!
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
(논문 발행일 : 2020.10, 세미나 발표일 : 2023.12.20)
https://github.com/google-research/vision_transformer
GitHub - google-research/vision_transformer
Contribute to google-research/vision_transformer development by creating an account on GitHub.
github.com
[서론]
- NLP에 사용되는 일반적인 Transformer : Self-attention 기반의 구조

- 그림과 같이, encoder-decoder 구조였음
- NLP에서는 이러한 구조가 지배적임
그럼, 컴퓨터 비전 분야에서는 ?
- 대다수의 딥러닝을 하는 사람들이 알고 있듯이, CNN이 지배적임
- CNN으로 이미지의 피쳐맵을 추출해서, 분류/인식 등과 같은 작업을 진행함
- ViT는 NLP Transformer에 영감을 받아, 이미지에 직접적으로 대입
먼저, Attention과 self-attention의 차이점을 보겠음
- Attention : Seq2Seq에서 사용
- 직전 번역 정보와 비슷한 정보일 수록 더 중요하게 생각하겠다는 의미임
- Self-attention : Transformer에서 사용
- 정보 전체의 '문맥'을 고려하여 가중치 계산
- 즉, 기존의 attention 기법은 직전 출력값과 dot 연산을 수행하였음
- Self-attention은 자기 자신과 dot 연산을 수행하여 좀 더 문맥을 고려하여 계산을 수행함

Transformer vs. Vision Transformer
- Transformer : 기존 NLP에 주로 사용됨

- Vision Transformer : Transformer를 vision task에 적용

- 이미지 Feature map 비교 (CNN vs ViT)
- 그림을 보면, ViT가 CNN보다 더 특징을 뚜렷하게 보여주는 것을 확인 할 수 있음

[방법]
ViT의 전반적인 구조

과정은 아래와 같음
- 이미지를 고정된 크기의 패치로 분할
- 각 패치 별 임베딩 실행
- Position 임베딩을 추가함
- 일련의 시퀀스 (Patch + Position 임베딩)를 Transformer 인코더에 입력
- 이때, 학습 가능한 분류 토큰 (클래스 임베딩)을 입력 시퀀스 맨 앞에 추가
패치화
- 2D 이미지를 사용함
- 펼쳐진 2D 패치들의 시퀀스로 이미지 reshape
- 2D 이미지 shape : (H, W, C)
- HxW : 이미지의 기존 해상도, C : 채널
- 2D patch shape : (N x (P^2, C)
- PxP : 이미지 패치 해상도
- N = HW / (P^2) → 패치 수
- 원본 이미지의 사이즈가 256이라고 한다면, N = 4, P = 128이 됨

- 패치들을 펼침 (Flatten)
- 각각의 패치들을 D차원으로 임베딩


임베딩
- 각각의 패치를 D차원으로 임베딩 → 패치 임베딩
- 그림에서 임베딩 앞에 0~9로 표시 → 포지션 임베딩
- 임의의 값으로 초기화 해준 뒤, 학습을 통해 적절한 벡터를 찾음



- N : 패치의 수
- xE(p~N) : Patch Embedding
- E_pos : Position embedding (학습 가능한 파라미터)
- x_class : 클래스 토큰 임베딩
- 처음에는 의미 없는 벡터
- 학습 완료 후에는 입력 이미지를 분류하기 위한 정보를 포함하는 벡터가 됨
- Position 임베딩도 똑같이 해줌
- 이러한 임베딩 들이 ViT 인코더에 입력됨

Transformer Encoder
- 배치 정규화 : 배치 당 feature 정규화
- 레이어 정규화 : 각 입력마다 정규화 (배치와 무관) - ViT 에선 레이어 정규화 실행


- 앞에서 수식으로 정의된 z가 Transformer encoder에 입력됨

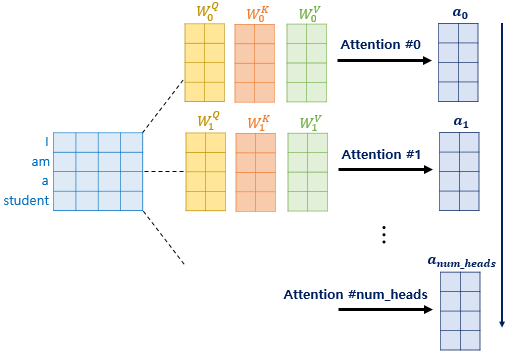
Multi-head attention
- 구글 리서치에 따르면 한 번에 계산하는 것 보다 여러 개를 나누어 병렬 계산하는 멀티 헤드 어텐션 메커니즘이 성능이 더 좋다고 함
- 예) 사람이 혼자 vs 여러 사람 (팀프로젝트)
- 같이하면 좋잖아 !!

MLP Block
- 두 개의 Dense 레이어로 구성 : 사이즈는 실험마다 다름
- GeLU 활성화 함수 사용 (Gaussian error linear units) : NLP에 주로 많이 사용됨

- L 개의 transformer encoder를 쌓음
- 첫 번째 레이어의 output → 다음 레이어의 input
MLP head
- Transformer encoder의 맨 마지막이 MLP를 두개 실행
- 두 레이어를 실행한 이후 출력된 결과의 첫번째 행
- 여기서 클래스 토큰 부분만 가져와서 분류 문제에 사용
- 머리 부분을 가져오기 때문에 MLP head 라고 부름

하이브리드 구조
- Raw 이미지 패치가 아닌 CNN을 통한 feature map을 input 시퀀스로 삽입
- 이 경우에는 패치의 크기를 1로 설정 → 바로 flatten
- 실험 성능 비교에 사용됨
[실험]
학습을 위한 데이터 셋
- 많은 데이터로 pretrain 진행
- ILSVRC-2012 ImageNet Dataset : 1.3M images with 1k classes
- ImageNet-21k dataset : 14M images with 21k classes
- JFT dataset : 303M high-resolution images with 18k classes
파인 튜닝을 위한 데이터 셋
- ImageNet
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- 19-task VTAB classification suite
- Natural - Pets or CIFAR
- Specialized - 메디컬, 위성 이미지
- Structured - 위치와 같은 기하학 이미지
모델 다양성
- ViT-L/16 : "Large" variant with 16x16 input patch size
- 패치 사이즈가 줄어들수록 시퀀스 길이는 늘어나므로 계산 비용 오래 걸림

파라미터
- 학습 : Adam, batch size : 4096, weight decay : 0.1
- Fine-tuning : SGD, batch size : 512
이미지 분류 성능 비교
- TPUv3 사용해서 학습 진행
- TPUv3-core-days : 학습에 사용되는 TPUv3 코어 수 x 하루 동안의 학습 시간
- 대용량 데이터로 pre-train을 했을 때 성능이 좋음

- Vit-H/14의 성능이 제일 좋음.
- TPUv3-core-days 값이 작을 수록 좋은 것임
VTAB 데이터셋 사용 시 성능
- 다른 이미지 분류 모델에 비해 ViT이 항상 더 높은 성능을 가짐
- 여기서 BiT나 S4L은 일반 ResNet을 뜻함

JFT-300M 데이터 사용 시 성능 비교
- Vit이 가장 우수한 성능을 가짐
- 작은 데이터셋에서 사전 학습 될 수록 ViT는 일반 ResNet보다 낮은 성능


연산량에 따른 성능 비교
- JFT-300M에 대해 사전 학습 수행
- ViT, Hybrid가 resNet보다 연산량은 많지만 정확도가 더 높음

시각화
- ViT-L/32의 패치 임베딩 필터
- 첫번째 레이어 시각화 - CNN 필터와 유사하게 이미지 특징을 학습

- 학습 파라미터에 따라 달라지는 position 임베딩 결과

[결론]
- ViT를 다른 컴퓨터 비전 task에 적용 : Detection and segmentation
- 더 큰 데이터셋으로 네트워크를 학습해야 할 필요가 있음
- 현재 DiT (Diffusion Transformer)를 도입하여 Image generation domain에 새로운 시도 진행 : 2022년 12월
- CNN 도메인만 공부하던 연구자로써, ViT가 처음 도입 됐을때 공부를 그만 둔 것이 내심 아쉬움
- 마지막으로 세미나를 진행한 논문이 이 논문인데, 만약 공부를 계속했다면 이걸로 여러 가지 시도해 보았을텐데 꽤나 아쉬움
- 다음에는, 코드 실행도 해봐야지 생각 중임 (언젠가..?)
[Ref] 아래는 참고한 블로그 사이트임
더 자세한 설명이 잘 되어 있으므로 참고하는 것도 Good! 다들 감사합니다 이해에 많은 도움이 되었어요 :)
https://engineer-mole.tistory.com/133
[논문] 최근 AI의 이미지 인식에서 화제인 "Vision Transformer"에 대한 해설
※ 일본 블로그 내용을 번역한 것으로 오역이나 직역이 있을 수 있으며, 내용의 오류 지적해주시면 감사하겠습니다. 1. 개요 현재 AI계에서 화제가 되고 있는 "Vision Transformer"에 대해 다뤄보려고
engineer-mole.tistory.com
https://codingopera.tistory.com/44
(multi head attention 설명)
4-2. Transformer(Multi-head Attention) [초등학생도 이해하는 자연어처리]
안녕하세요 '코딩 오페라'블로그를 운영하고 있는 저는 'Master.M'입니다. 현재 저는 '초등학생도 이해하는 자연어 처리'라는 주제로 자연어 처리(NLP)에 대해 포스팅을 하고 있습니다. 제목처럼 진
codingopera.tistory.com
https://kwonkai.tistory.com/144
(layer normalization 설명)
Batch Normalization VS Layer Normalization
Normalization(정규화)이란? Normalization(정규화)의 목적은 모든 데이터들의 스케일을 동일하게 만들어서 각 feature 값들이 동등한 중요도를 가지도록 하는 작업이다. 정규화 되지 않은 Un-normalization 그
kwonkai.tistory.com
https://davidlds.tistory.com/13
[논문 리뷰] Vision Transformer(ViT) 요약, 코드, 구현
논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다. 나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다. ViT AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE DOSOVITS
davidlds.tistory.com
https://nlpinkorean.github.io/illustrated-transformer/
The Illustrated Transformer
저번 글에서 다뤘던 attention seq2seq 모델에 이어, attention 을 활용한 또 다른 모델인 Transformer 모델에 대해 얘기해보려 합니다. 2017 NIPS에서 Google이 소개했던 Transformer는 NLP 학계에서 정말 큰 주목을
nlpinkorean.github.io
https://ffighting.net/deep-learning-paper-review/language-model/transformer/
(self-attention 설명)
Transformer 논문 리뷰 - ChatGPT 모델의 근간 확실하게 이해하기
Transformer 논문의 핵심 내용을 살펴봅니다. Transformer의 구조, Self Attention의 힘, 그리고 실제 실험 결과를 소개합니다. Transformer의 장단점과 중요성도 함께 알아봅니다.
ffighting.net



