
꿈꾸는 개발자의 devLog
[Object Detection - 2] 딥러닝 : 객체 인식 본문
객체 인식은 2013년 R-CNN이 나오면서 딥러닝을 사용하기 시작함

객체 인식을 위해 주로 사용했던 방법 : 슬라이딩 윈도우

저 파란 박스가 왼쪽에서부터 오른쪽으로 움직이면서 개가 있는지 또는 고양이가 있는지 등 확인을 함
근데 이러기 위해선 정말 많은 파란 박스가 필요하기 때문에 비용적으로 비효율적임
또, 이미지에 어떤 객체가 있을지 알 수가 없음
그만큼 경우의 수가 다양해짐
Region Proposals
그래서 나온게 region proposal이라는 방법임
이 방법은 딥러닝을 사용하는게 아님
Object가 있을법한 BBox를 제공해 줌
이미지 내에 뭉텅진 곳(Blobby)을 찾아냄 : 객체가 있을지도 모르는 후보 영역

Selective search
Region proposal을 만들어낼 수 있는 방법 중 하나
- 2000개의 bounding box를 찾아냄
- 입력 영상에 대해 segmentation 실시, 이를 기반으로 후보영역을 찾기 위한 시드 설정
- 주변 픽셀 간의 유사도를 기준으로 segmentation 생성
- 초기에 많은 후보들이 만들어지지만, 이 과정들을 반복해 나감
- 후보 영역의 개수가 줄어들고 box 수도 줄어들게 됨

그럼, 이러한 region proposal 방법을 활용한 것 중 하나가 R-CNN
R-CNN

- 먼저, region proposal 단계에서 RoI를 찾음 (위에서 언급된 방법 활용)
- 이때, RoI의 사이즈는 각양 각색임
- 추출된 RoI로 CNN 분류를 수행하기 위해서 같은 입력 사이즈로 맞춰줘야함
- 고정된 사이즈로 크기 변경 (224x224 크기로 변경)
- 그런 다음, ConvNet에 통과 시킴 (AlexNet 구조 사용)
- 최종적으로 4096 차원의 feature vector를 추출해냄
- SVM에 각각의 feature vector들의 점수를 클래스 별로 할당
- BBox Regression
- 처음에 정답 박스와 cnn을 통과해서 나온 box 두가지의 차이를 줄이도록 조정하는 모델
* R-CNN 단점
- 2,000개 각각의 region proposal이 CNN 입력으로 들어가기 때문에 계싼비용이 매우 높음
- 학습 과정 자체가 상당히 오래 걸림
이러한 단점을 극복한게 Faster R-CNN (다음 글에서!)
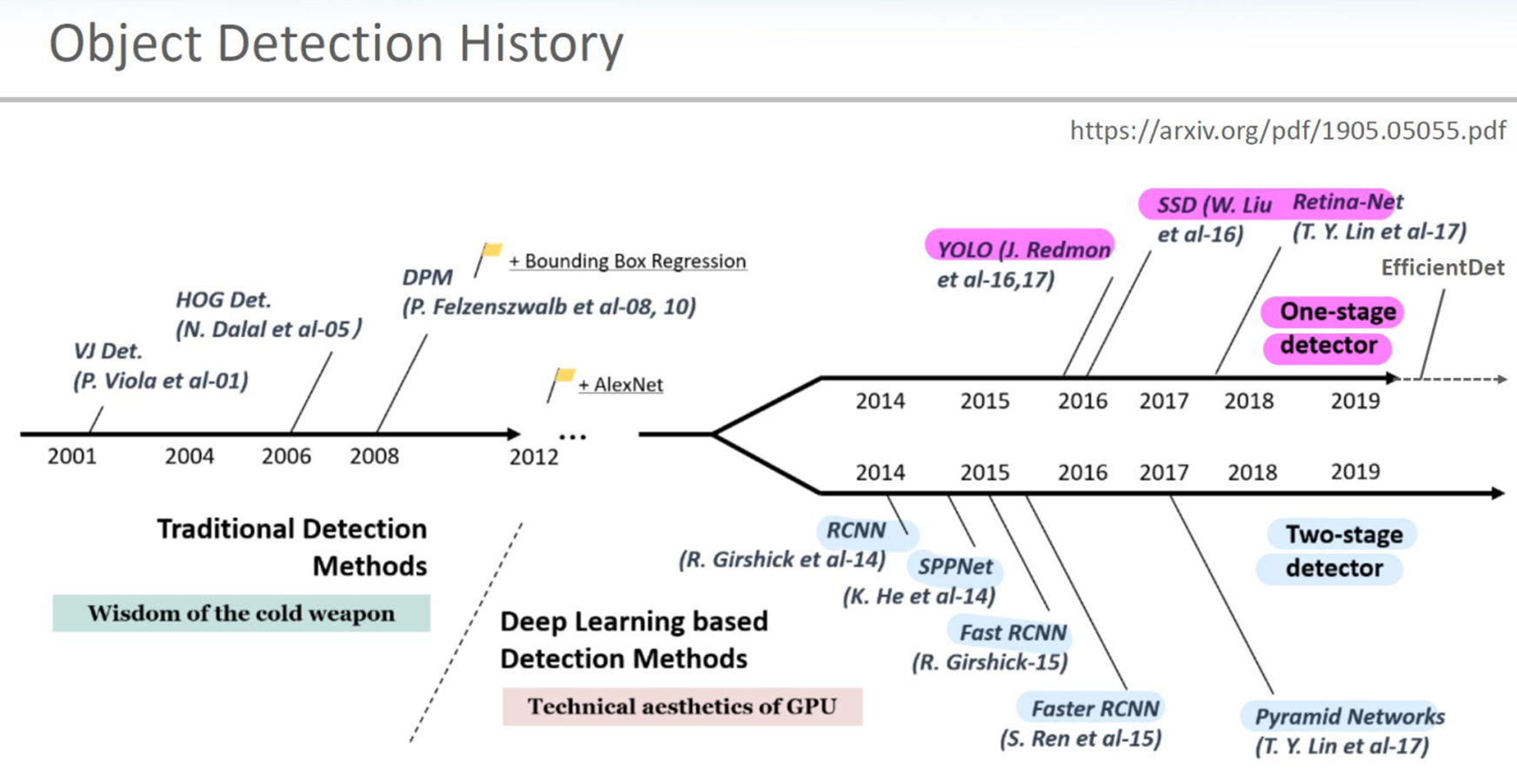
- one-stage/two-stage 차이는 YOLO 공부하면서 할 예정!
객체 인식의 처음 흐름에 대해서 살펴 보았음
예전에 객체 인식을 처음 공부할때, region proposal이라는 부분이 정말 이해가 가질 않았는데
시간이 지나고 보니깐 사실은 정말 간단한 개념이었다..
그땐 왜그렇게 어려웠는지..
Ref
https://velog.io/@whiteamericano/R-CNN-%EC%9D%84-%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90
R-CNN 을 알아보자
딥러닝(CNN)을 Object Detection 분야에 최초로 적용시킨 모델이며 이전의 Object Detection 모델에서 성능을 상당히 향상시키고, 이후 Fast R-CNN, Faster R-CNN, Mask R-CNN을 나오게 한 의미있는 모델인 R-CNN에 대
velog.io
https://ganghee-lee.tistory.com/35
(논문리뷰) R-CNN 설명 및 정리
컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다. 1. Classification 2. Object Detection 3. Image Segmentation 4. Visual relationship 이중에서 4. Visual relationship은 나중에 다루고 먼저 위 3개의 차이를
ganghee-lee.tistory.com
'Study > Deep Learning' 카테고리의 다른 글
| [Object Detection - 3] 딥러닝 : 객체 인식 (0) | 2024.06.19 |
|---|---|
| [Object Detection - 1] 딥러닝 : 객체 인식 (0) | 2024.06.10 |
